3.数据的降维 DataFrame 有个apply方法,就是把函数映射到 DataFrame 里面每个 Series 上,对 Series 进行操作。这是一种降维操作。
import numpy as np import pandas as pd df = pd.DataFrame(np.arange(20).reshape(4,5)) print(df) 先把pd.DataFrame转为numpy.ndarray类型 dd = np.array(df) print(dd) 之后转为列表 ss = dd.tolist() print(ss) 完整代码: import numpy as np import pandas as pd df = pd.DataFrame(np....
EN在数据表或 DataFrame 中有很多识别缺失值的方法。一般情况下可以分为两种:一种方法是通过一个覆盖全...
FirstLevelModel expects a pd.DataFrame and rejects a np.array:nilearn/nilearn/stats/first_level_model/first_level_model.py Lines 359 to 366 in f03f725 confounds: pandas Dataframe or string or list of pandas DataFrames or strings Each column in a DataFrame corresponds to a confound ...
df_columns = pd.DataFrame.from_dict(d,orient='columns') df_columns 1 2 输出结果为: a b c fp 112 91 74 tp 26 26 23 1 2 3 通过传递一个numpy array,时间索引以及列标签来创建一个DataFrame data = DataFrame(np.arange(10,26).reshape((4, 4)), ...
return pd.DataFrame(np.array(l).T,columns=list_set(df_data[df_title_X].to_list()), index=list_set(df_data[df_title_X].to_list())) print(func(df,'减肥方式','血压含量')) 结果如下: 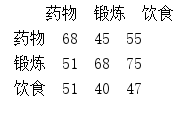 ...
我正在为现有的pd.read_table(path/to/file, index_col=[0,1])寻找类似于pd.DataFrame的东西。DataFrameDF_B =pd.DataFrame=pd.concat([DF_A,
a1=S1.tolist() b1=S2.tolist() 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 4.DataFrame DataFrame:可以直接把它想象成Excel表格,有行表头与列表头,表头可以自己定义,可以是非数字的 a=pd.DataFrame(np.random.rand(4,5),index=list("ABCD"),columns=list('abcde')) ...
可以用DataFrame.dtypes属性来查看数据格式。 df_consume.dtypes 1. 格式如下: 基金名称 object 基金代码 object 基金经理 object 性别object 上任日期 datetime64[ns] 基金公司 object 管理费 float64 托管费 float64 基金规模(亿) float64 规模对应日期 datetime64[ns] ...
read_csv()函数在pandas中用来读取文件(逗号分隔符),并返回DataFrame。 2.参数详解 2.1 filepath_or_buffer(文件) 注:不能为空 filepath_or_buffer: str, path object or file-like object 1 设置需要访问的文件的有效路径。 可以是URL,可用URL类型包括:http, ftp, s3和文件。