df_columns = pd.DataFrame.from_dict(d,orient='columns') df_columns 1 2 输出结果为: a b c fp 112 91 74 tp 26 26 23 1 2 3 通过传递一个numpy array,时间索引以及列标签来创建一个DataFrame data = DataFrame(np.arange(10,26).reshape((4, 4))
3.数据的降维 DataFrame 有个apply方法,就是把函数映射到 DataFrame 里面每个 Series 上,对 Series 进行操作。这是一种降维操作。
所以一般会选择生成一个空字典,空list/array来保存,然后转成DataFrame,保存为csv。这样期间修改,也很容易更新。 但这样就带来新问题,如何有效率的生成这样的df,然后让其保存起来更好看直观呢?在翻旧书的时候,发现pd有MultiIndex的功能,就挺符合,多种模型,多个指标并列的输出,类似如下图 很多功能虽然很有用,但平常...
The problem is that I can't work out how to do this. The only real option I've found is a complete r...gojs - adding port controllers I have a node template in go.js with a "topArray" that might contain a several ports like in this example. For each top port I want to ...
中DataFrame的基本使用,很多高级用法和技巧需要结合实际业务场景来使用。...在内部,Series将值存储在普通的NumPy vector中。因此,它继承了它的优点(紧凑的内存布局、快速的随机访问)和缺点(类型同质、缓慢的删除和插入)。...pdi中find()和findall()两个简单的封装器,它
可以用DataFrame.dtypes属性来查看数据格式。 df_consume.dtypes 1. 格式如下: 基金名称 object 基金代码 object 基金经理 object 性别object 上任日期 datetime64[ns] 基金公司 object 管理费 float64 托管费 float64 基金规模(亿) float64 规模对应日期 datetime64[ns] ...
js中的数组对象排序(方法sort()详细介绍) 定义和用法 sort() 方法用于对数组的元素进行排序。 语法 arrayObject.sort(sortby) 参数sortby:可选。规定排序顺序。必须是函数。 返回值 对数组的引用。请注意,数组在原数组上进行排序,不生成副本。 普通......
2. 使用.values属性将DataFrame转换为NumPy数组 .values属性是Pandas早期版本中用于将DataFrame转换为NumPy数组的方法。它返回一个包含DataFrame数据的NumPy数组。 python # 使用.values属性转换 numpy_array_values = df.values print(numpy_array_values) print(type(numpy_array_values)) 3. 使用.to_numpy()方法将...
return pd.DataFrame(np.array(l).T,columns=list_set(df_data[df_title_X].to_list()), index=list_set(df_data[df_title_X].to_list())) print(func(df,'减肥方式','血压含量')) 结果如下: 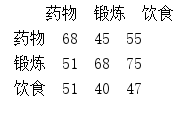 ...
EN在数据表或 DataFrame 中有很多识别缺失值的方法。一般情况下可以分为两种:一种方法是通过一个覆盖...