momentum动量法momentum动量法 动量法是一种优化方法,可以帮助算法在局部最优解附近更快地收敛。其优点有: - 可以帮助算法“跳过”局部最小值,保持一定的加速度,使算法能够跨越那些低点。 - 可以减少学习率的需求,因为动量法可以帮助算法跳过局部最小值,所以我们不需要设置过大的学习率来更快地收敛,这可以减少学习...
动量方法直白解释: 如图所示,红色为SGD+Momentum。黑色为SGD。可以看到黑色为典型Hessian矩阵病态的情况,相当于大幅度的徘徊着向最低点前进。 而由于动量积攒了历史的梯度,如点P前一刻的梯度与当前的梯度方向几乎相反。因此原本在P点原本要大幅徘徊的梯度,主要受到前一时刻的影响,而导致在当前时刻的梯...
动量方法通过引入一个“速度”变量v,来积累之前梯度的指数级衰减平均,并继续沿该方向移动。这样,即使当前梯度与历史梯度方向相反,由于动量的存在,模型参数也不会出现大幅度的徘徊,而是能够在一定程度上保持前进的方向,从而加速收敛。 在实际应用中,动量方法的效果非常显著。一般来说,我们将动量参数设为0.5、0.9或0.99,...
引入动量中间变量vt,在时间步t>0,动量法对每次迭代的步骤做如下修改: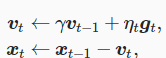动量法使用了指数加权移动平均的思想。它将过去时间步的梯度做了加权平均,且权重按时间步指数衰减。动量法使得相邻时间步的自变量更新在方向上更加一致。
Momentum 动量法,顾名思义,在梯度的计算过程中增加了动量信息,从百度百科可以看到 物理学上讲的动量是与速度方向有关的量。在动量法梯度下降中,同样也是应用了这个原理,它是在当前样本梯度的基础上,以指数加权平均的方式将上一步的梯度累加到当前样本梯度之上,形成最终...
Momentum动量 首先讲动量方法,它的基本迭代通常可以表述为 vt=μt−1vt−1−ϵt−1∇g(θt−1)θt=θt−1+vt (1) 这里的 μt−1<1 表示衰减因子,可以理解为对以前方向的依赖程度,注意到如果 μt−1=0 ,那就变成了普通的梯度方法了。有时会看到下面这种写法: vt=μt−1vt−1...
sgd 随机梯度 动量法(momentum)SGD(随机梯度下降法)是一种常用的机器学习优化算法,其基本思想是在每次迭代时,使用样本中的一个随机子集(小批量)来近似计算梯度。相比于传统的全批量梯度下降法,SGD能够在数据样本量大时显著降低计算复杂度和存储空间需求,加速模型的收敛速度。 而动量(momentum)方法则是SGD的一种改进...
而一个真正的小球要比这聪明多了,从A点滚动到B点的时候,小球带有一定的初速度,在当前初速度下继续加速下降,小球会越滚越快,更快的奔向谷底。momentum 动量法就是模拟这一过程来加速神经网络的优化的。 后文的公式推导不加特别说明都是基于 mini-batch SGD 的,请注意。
简述动量Momentum梯度下降 梯度下降是机器学习中用来使模型逼近真实分布的最小偏差的优化方法。 在普通的随机梯度下降和批梯度下降当中,参数的更新是按照如下公式进行的: W = W - αdW b = b - αdb 其中α是学习率,dW、db是cost function对w和b的偏导数。 随机梯度下降和批梯度下降的区别只是输入的数据...
Momentum(动量指标)基本用法 Momentum 指标简称 MTM,中文称为动量指标。该指标是用来衡量价格趋势变化的速度。 MTM 指标属于mt4自带的技术指标,在mt4上方菜单栏依次点击-插入-技术指标-震荡指标- Momentum,即可将 MFI 指标插入到当前图表中... Momentum 指标简称 MTM,中文称为动量指标。该指标是用来衡量价格趋势变化的...