答:BERT的结构不能简单地用LSTM替换。BERT模型采用的是Transformer结构,而LSTM则是一种递归神经网络结构,二者在结构和运算方式上有很大的不同。 Transformer结构的优点在于其能够并行计算,使得训练速度更快,并且可以处理更长的文本序列。而LSTM则需要按照时间步序列逐步计算,训练速度较慢,并且无法很好地处理长文本序列。
我们尝试将 Bert 模型应用在 query-title 分档任务上,将 query 和 title 作为句对输入到 bert 中,取最后一层 cls 向量用做 5 分类(如上图),最后得到的结果比 LSTM-Attention 交互式匹配模型要好。虽然知道了 bert能解决这个问题,我们更好奇的是"为什么":为什么 bert 的表现能这么好?这里面有没有可解释的部...
"params": [p for n, p in robert_lstm_att.lstm.named_parameters() if not any(nd in n for nd in no_decay)], "weight_decay": ARGS.WeightDecay, "lr": ARGS.learning_rate*10 # LSTM层的学习率 }, { "params": [p for n, p in robert_lstm_att.lstm.named_parameters() if any(nd...
这种双向技术能充分提取语料的时域相关性,但同时也大大增加了计算资源的负担。【关于Transformer是Google 17年在NLP上的大作,其用全Attention机制取代NLP常用的RNN及其变体LSTM等的常用架构,大大改善了NLP的预测准确度。本文不展开,该兴趣的同学可以自行搜索一下】。 图4 【图4】Pretrain架构对比。其中OpenAI GPT采用从...
Transformer 已迅速成为 NLP 的主要架构,在自然语言理解和自然语言生成任务的性能上超过了 CNN、RNN 和 LSTM 等替代神经模型。让我们快速了解一下Transformer 。 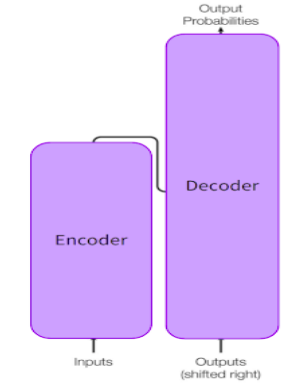 Transformers 用于在执行序列到序列建模时学习句子中单词之间的长期依赖关系。通过解决可变长度输入...
递归神经网络从下到上构建序列的表示,这一点不同于从左到右或从右到左处理句子的 RNN。在树的每个节点上,通过组合子节点的结果来计算新的结果。由于树也可以被视为在 RNN 上强加不同的处理顺序,所以 LSTM 自然地也被扩展到树上(Tai等,2015)。
BERT-BiL-Att融合模型机制 在采用BERT模型进行词向量训练的基础上,结合BiL-Att模型进行中医医学文本抽取与分类。Bi-LSTM与Attention融合模型就是在Bi-LSTM的模型上添加Attention层,在Bi-LSTM中用最后一个时序的输出向量作为特征向量,选择Softmax函数进行分类,Attention模...
我们尝试将 Bert 模型应用在 query-title 分档任务上,将 query 和 title 作为句对输入到 bert 中,取最后一层 cls 向量用做 5 分类(如上图),最后得到的结果比 LSTM-Attention 交互式匹配模型要好。虽然知道了 bert能解决这个问题,我们更好奇的是"为什么":为什么 bert 的表现能这么好?这里面有没有可解释的部...
论文在最一开始就与另外两个pretrain模型:ELMo和OpenAI GPT做了对比,从结构上我们可以看出ELMo的基础是使用了LSTM,而OpenAI GPT和BERT使用了Transformer作为基本模型。注意BERT一些核心的创新点: 相较于OpenAI GPT模型而言,其为双向Transformer; 而同是双向,ELMo由于是基于LSTM,BERT基于Transformer,并且核心的是两者的目标...
阅读本系列文章需要一些背景知识,包括Word2Vec、LSTM、Transformer-Base、ELMo、GPT等,由于本文不想过于冗长(其实是懒),以及相信来看本文的读者们也都是冲着BERT来的,所以这部分内容还请读者们自行学习。 本文假设读者们均已有相关背景知识。 目录 3、序列分类 ...