二、代码实现 多智能体深度确定性策略梯度(Multi-Agent Deep Deterministic Policy Gradient, MADDPG)算法是一种在多智能体环境中使用的强化学习算法。这种算法是基于深度确定性策略梯度(DDPG)算法的扩展。MADDPG主要用于解决多智能体环境中的协作和竞争问题,特别是在智能体之间的交互可能非常复杂
多智能体强化学习 MADDPG 纯白板逐行代码Python实现施莱登对你很施旺编辑于 2025年02月07日 15:58 这里这么改,不要像up一样进行actions_tensor.detach()分享至 投诉或建议评论 赞与转发0 0 0 0 0 回到旧版 顶部登录哔哩哔哩,高清视频免费看! 更多登录后权益等你解锁...
下载maddpg-master.zip和multiagent-particle-envs-master.zip,解压缩后放在一个文件夹下,然后把他放在prompt默认得文件夹中,我的在user/ymz/文件夹下。 打开prompt,cd到这两个文件夹的大文件夹里。 运行命令pip install -e maddpg-master,安装所有配置。 运行命令pip install -e multiagent-particle-envs-master。
MADDPG(Multi-Agent Deep Deterministic Policy Gradient)作为一种深度强化学习算法,在多智能体协作中表现出了良好的效果。本文将用PyTorch来实现MADDPG,并提供必要的代码示例,以方便读者理解算法的实现过程。 MADDPG算法简介 MADDPG是基于DDPG(Deep Deterministic Policy Gradient)的扩展,主要用于处理多智能体场景中的部分可...
MADDPG原理入门笔记与基于PARL框架的代码实现MADDPG原理入门笔记:背景与挑战:在多智能体环境中,传统的强化学习方法可能面临不稳定性和训练困难,因为每个智能体的策略变化会相互影响。MADDPG简介:MADDPG是为了应对多智能体环境挑战而提出的方法。它基于DDPG算法,通过引入多智能体结构,使每个智能体能够从全局...
多智能体强化学习 MADDPG 纯白板逐行代码Python实现施莱登对你很施旺编辑于 2025年02月07日 15:58 这里这么改,不要像up一样进行actions_tensor.detach()分享至 投诉或建议评论 赞与转发0 0 0 0 0 回到旧版 顶部登录哔哩哔哩,高清视频免费看! 更多登录后权益等你解锁...
MADDPG官方代码实现 Ubuntu16.04+window10两个系统都实现了 Ubuntu系统安装方法: 参考地址:http://ddrv.cn/a/320291 环境要求: 安装gym pip install gym 安装环境: git clonehttps://github.com/openai/multiagent-particle-envs 解压缩后,进入到文件夹内,输入命令...
MADDPG官方代码实现 2020-07-25 14:45 −... Fiona_Y 3 3417 ArrayList实现原理(JDK1.8) 2019-11-30 19:14 −### ArrayList实现原理(JDK1.8) 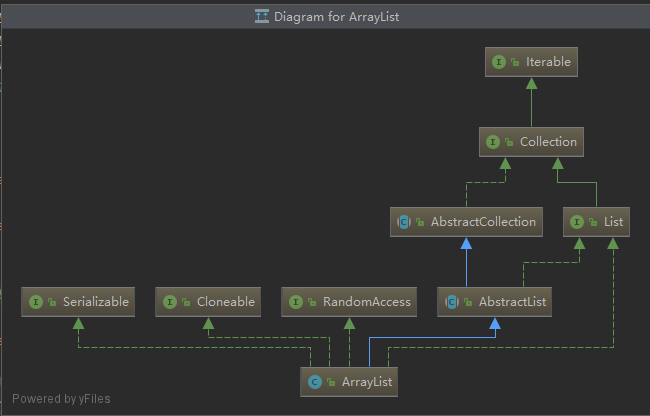 ``` java public class ArrayLis... ...
具体的算法实现大家可以去 github.com/PaddlePaddle 上去看。 MADDPG算法简介 上图是论文里面MADDPG的伪代码,可以看到MADDPG和DDPG是类似的,但最主要的不同在于:在DDPG算法中,Critic(评论家)的输入是自身的观测-行动数据(observation-action),而MADDPG中,每个Agent的Critic除了输入自身的observation、action信息外,还有其他...